Comparing Achronix Speedster7t FPGAs to GPU solutions for running the Llama2 70B parameter model and exceeding LLM inference processing demands.
Delivering FPGA-Accelerated LLM Performance
How do Speedster7t FPGAs stack up against GPU solutions when running the Llama2 70B parameter model? The evidence is compelling — Achronix Speedster7t FPGAs outperform in processing large language models (LLMs) by delivering an optimal combination of computational power, memory bandwidth, and exceptional energy efficiency — essential qualities for the sophisticated demands of today’s LLMs.
The rapid advancement of LLMs such as the Llama2 is charting a new course for natural language processing (NLP), promising to deliver more human-like interaction and understanding than ever before. These sophisticated LLMs are catalysts for innovation, driving the need for advanced hardware solutions to meet their intensive processing demands.
Our benchmarks highlight the Speedster7t family’s ability to handle the Llama2 70B model’s complexity, focusing on FPGA and LLM performance. These tests (results available upon request) show the potential of Achronix FPGAs for developers and enterprises that want to use the power of LLMs for their NLP applications. These benchmarks demonstrate how the Speedster7t FPGA outperforms the market, delivering unparalleled performance while reducing operational costs and environmental impact.
Llama2 70B LLM on Speedster7t FPGAs
In July 2023, Microsoft and Meta unveiled their open-source LLM, Llama2, setting a new precedent in AI-driven language processing. Llama2 is engineered with multiple configurations to cater to various computational needs, including 7, 13, and 70 billion parameters, positioning it at the forefront of LLM innovation. Achronix and our partner, Myrtle.ai conducted an in-depth benchmark analysis of the 70 billion parameter Llama2 model, showcasing the advantages of using Speedster7t FPGAs for LLM acceleration.
Benchmark Results: Speedster7t FPGAs vs. Industry-Leading GPUs
We tested the Llama2 70B model’s inference performance on the Speedster7t FPGA and compared it with leading GPUs. This benchmark was done by modeling an input, output sequence length of (1,128) and a batch size =1. The results showed the Speedster7t AC7t1500 effectiveness in LLM processing.
The FPGA cost was based on the list price for a VectorPath accelerator card powered by a Speedster7t FPGA. Similarly, we used the list price of the comparable GPU card in this analysis. Using this cost information and the number of output tokens produced per second, we computed a 200% improvement in $/token for an FPGA-based solution. In addition to the cost advantages, when comparing the relative power consumption of the FPGA and GPU card, we observed a 200% improvement in the kWh/token produced compared to a GPU-based solution. These benefits show how FPGAs can be a cost and power-effective LLM solution.
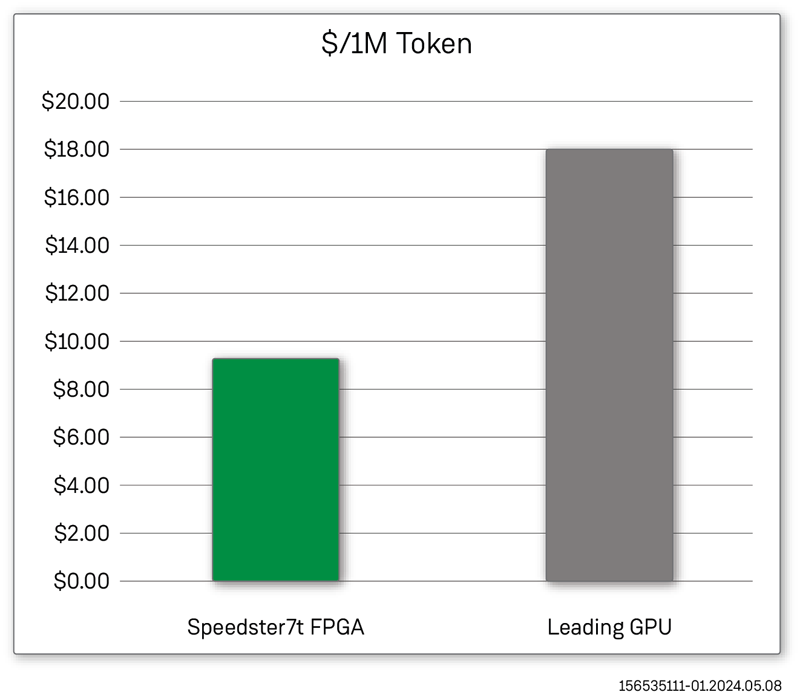
Speedster7t FPGAs Outperform Leading GPUs on a Cost/Token Basis
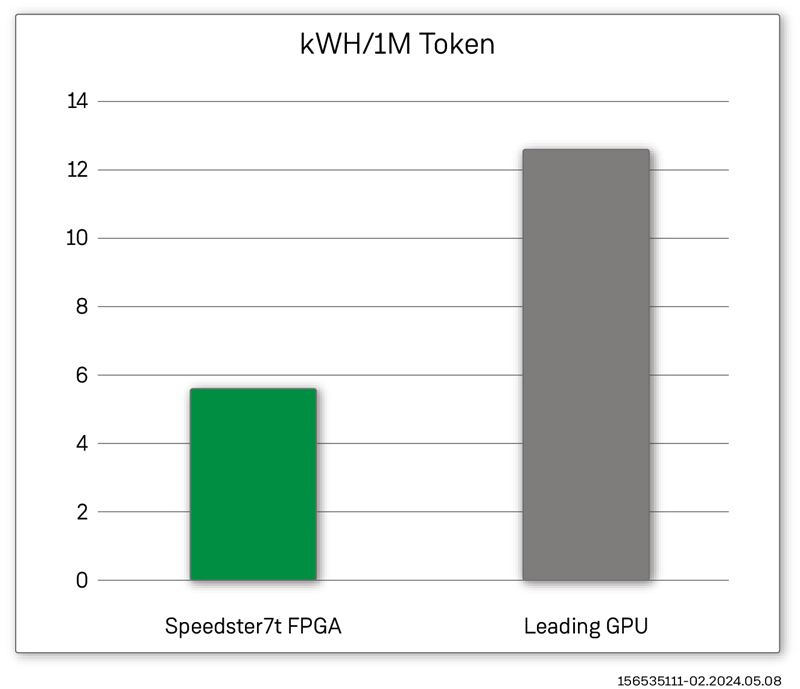
Speedster7t FPGAs Outperform Leading GPUs on a Power/Token Basis
FPGAs for LLM: The Speedster7t Advantage
The Achronix Speedster7t family of FPGAs were designed to optimize LLM operations, balancing the key requirements for LLM hardware, including:
- High-performance compute – Cutting-edge hardware with high-performance computing capabilities are essential to manage the intricate matrix calculations central to LLM inference.
- High-bandwidth memory – Efficient LLM inference relies on high-bandwidth memory to rapidly feed data through the model’s network parameters without bottlenecks.
- Ability to scale and adapt – Modern LLM inference necessitates hardware that can scale with the model’s growing size and adapt flexibly to continuous advancements in LLM architectures.
- Power efficient processing – Sustainable LLM inference demands hardware that maximizes computational output while minimizing energy consumption to reduce operational costs and environmental impact.
Speedster7t FPGAs provide the following capabilities to address the challenges of implementing modern LLM processing solutions.
- Compute performance – Supports complex LLM tasks with its flexible machine learning processor (MLP) blocks.
- High GDDR6 DRAM bandwidth – Ensures swift processing of large LLM datasets with 4 Tbps of memory bandwidth.
- Substantial GDDR6 DRAM capacity – Accommodates expansive LLMs such as Llama2 with 32 GB capacity per FPGA.
- Integrated SRAM for LLMs – Provides low-latency, high-bandwidth storage with 190 Mb of SRAM ideal for storing activations and model weights.
- Versatile native number formats – Adapts to LLM needs with support for block floating point (BFP), FP16, bfloat16, and more.
- Efficient on-die data transport – Exceeds 20 Tbps with 2D NoC, streamlining on-chip data traffic.
- Expansive scale-out bandwidth – Meets LLM demands with 32, 112 Gbps SerDes, enhancing connectivity.
- Adaptive logic-level programmability – Prepares for rapid LLM advancements with a 690K 6-Input LUTs.
FPGAs Optimized for LLM Inference
Using FPGAs instead of GPUs to speed up LLMs is a fairly new idea in the fast-changing fields of AI and natural language processing. This benchmark shows how designers can benefit from using FPGA technology from Achronix. The Achronix Speedster7t family of FPGAs are a key technology in this change, offering a great balance of high performance, high-bandwidth memory, easy scalability, and power efficiency. Based on this detailed benchmark analysis, comparing the Speedster7t FPGA’s capabilities with leading GPUs in processing Llama2 70B model, the results show the Speedster7t FPGA’s ability to deliver high-level performance while greatly reducing operational costs and environmental impact, highlighting its important role in the future of LLM creation and use.
Contact Achronix to See How FPGAs can be Used to Accelerate your LLM Programs
We are excited about the future of FPGA accelerated LLM solutions. Please contact Achronix to receive the detailed benchmark results along with help determining how Achronix FPGA technology can accelerate your LLM designs.