Networking
Companies building future networks have the challenge of addressing the ever increasing and diverse data demands at an affordable cost. Two new paradigms that has evolved as a result are:
- Processing is moving closer to the data source rather than data moving to centralized compute resource for processing
- Software running in the cloud executing functions/tasks rather than on specialized hardware or local virtual machine
These factors are shaping the development of today's networks for the following reasons: strict latency requirements of emerging applications, sheer volume of data, the desire to optimize scarce networking resources and the need to connect billions of devices. As we look to the next decade, network infrastructure will become even more pervasive and integrated with every aspect of our everyday lives with the advent of technologies such as 5G, cloud, data center, to name a few. On one hand, 5G networks continue the paradigm of previous cellular standards in terms of driving bandwidth, but they also extend it to many more devices and usage models. Conversely, the rapid explosion in data-center network traffic driven by software-defined networking (SDN), Open vSwitch (OVS), and Network Functions Virtualization (NFV) demands a new class of evolving accelerator cards with continually greater offload capabilities.
The Speedster7t FPGA family is optimized for high-bandwidth workloads and eliminates the performance bottlenecks associated with traditional FPGAs. Built on TSMC’s 7nm FinFET process, Speedster7t FPGAs feature a revolutionary new 2D network-on-chip (2D NoC), an array of new machine learning processors (MLPs) optimized for high-bandwidth and artificial intelligence/machine learning (AI/ML) workloads, high-bandwidth GDDR6 interfaces, 400G Ethernet and PCI Express Gen5 ports — all interconnected to deliver ASIC-level performance while retaining the full programmability of FPGAs.
Speedster7t Solution
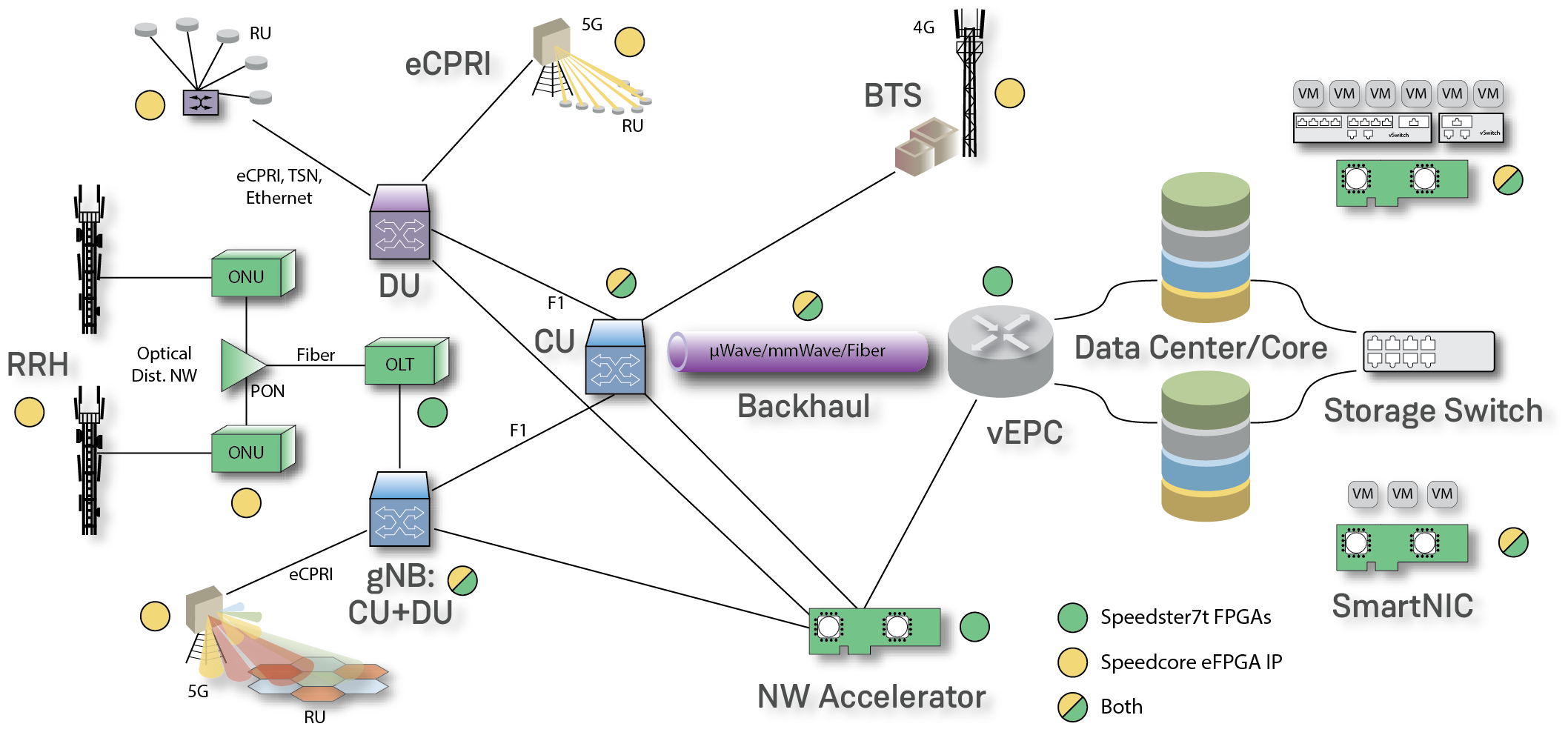
Many new and unique architecture features in Speedster7t FPGAs enable innovations in different networking technologies including 5G, network accelerators SmartNIC, high throughput packet processing and traffic management, and data-path security. Speedster7t FPGAs offer the highest performance interfaces including PCIe Gen5, fracturable Ethernet MACs up to 400G rates, GDDR6 for the highest bandwidth and lowest cost off chip storage, and DDR4/5 for large offchip bulk storage. Internally, Speedster7t FPGAs have been optimized to support high bandwidth data streams from these high performance interfaces with the new 2D Network on Chip (NOC) that enables efficient data transfers for multi Tbps of bandwidth in, out and across the FPGA fabric. An example of the aforementioned advantages is that Speedster7t FPGAs are the only FPGAs that can implement a Terabit Ethernet Switch (TbE) – a critical network entity for service and internet providers alike.
Speedster FPGAs Uniquely Support Full Bandwidth 400G Ethernet
Until recently, FPGAs have been at the center of Networking applications. In the past, designers would increase FPGA throughput by increasing the size of the buses that move data in the FPGAs. This methodology of increasing bus sizes no longer works. To support a 400G Ethernet stream, the FPGA would need to run a 1,024-bit bus at 724 MHz or a 2,048-bit bus at 642 MHz. Neither of these bus width options and FPGA performance are possible in today's most advanced FPGAs. However, Speedster7t FPGAs can easily run multiple 400G Ethernet datastreams using the new 2D NoC, which has dedicated circuitry to transfer the 400G data streams to the FPGA as 4 independent 100G data streams that are 256-bits at 506 MHz. Buses of this dimension and performance are easily managed in the Speedster7t fabric.
| Application Requirement | Speedster7t Value |
|---|---|
| Need for high-bandwidth external connectivity |
|
|
Highest memory bandwidth for buffering >1 Tbps |
Memory hierarchy
|
|
Wide and high performance data-path |
Dataflow fabric optimized for high throughput data transfer and acceleration
|
|
Substantial logic capacity to implement complex, custom algorithms |
Scalable family of devices up to 2.6M 6-input LUTs of logic |
|
Higher precision data formats for edge training efficiency |
|
| FPGA fabric for compute |
|
|
Substantial internal memory for queuing pointers, internal cache and scratchpad RAM |
Up to 300 Mb of internal SRAM |
| Access< | Transport (incl. 5G) | 5G Fronthaul | Network Accelerator (SmartNIC) | Network Test Equipment | Security Appliance | TbE Switch | |
|---|---|---|---|---|---|---|---|
|
Highest Performance SerDes |
|||||||
|
112G multi-standard SR/MR/LR PHY |
Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Ultra-short reach (USR), extra-short reach (XSR) |
Yes | Yes | Yes | Yes | Yes | Yes (Silicon Photonics) | |
|
Most Advanced Interface IP |
|||||||
|
400G Ethernet – 16 lanes each running up to 100G |
Yes | ||||||
|
SyncE, IEEE1588, Time Sensitive Networking |
Yes | Yes | Yes | Yes | Yes |
Yes |
|
|
PCIe Gen5, 512 Gbps per port |
Yes | Yes | Yes | Yes | |||
|
GDDR6 – 4 Tbps of memory bandwidth |
Yes | Yes | Yes | Yes | Yes | ||
|
DDR4 – up to 3,200 MHz, 3DS stacked memory |
Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
DDR5 – up to 4,400 MHz |
Yes | Yes | |||||
| Application-specific interface (e.g. CPRI) | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Terabit-Speed Routing |
|||||||
| Network on chip | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Bus routing | Yes | ||||||
|
Fully flexibility bit-wise routing |
|||||||
|
High-Throughput Processing |
|||||||
|
Packet Processor/Traffic Manager |
Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Datapath cryptography |
Yes | Yes | Yes | Yes | Yes | ||
|
Machine learning processor |
Yes | Yes | Yes | Yes | |||
|
Fine-grain hardware reprogrammability (examples listed) |
P4 – programmable pipeline |
P4 – programmable pipeline | Custom functions |
Network diagnostics |
Network diagnostics |
Application-specific cryptography |
P4 – programmable pipeline |